Prof. Howard Lee and Yoomin Jeon attended the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP 2018) held at the Square Meeting Center in Brussels from October 31st through November 4th, 2018. EMNLP is one of the top-tier conferences in the area of natural language processing organized by SIGDAT, the Association for Computational Linguistics (ACL) special interest group on linguistic data and corpus-based approaches to NLP. With the current artificial intelligence and machine learning boom from a variety of disciplines, this year's conference had a record-breaking number of submissions (2,231) and 2,500+ attendees, a 48% increase compared with EMNLP 2017. Of all the long and short papers submitted, only 549 papers were accepted, which can be found in the EMNLP proceedings. The conference included two days of workshops, followed by three days of main conference sessions including long and short presentations, tutorials, and demos. Researchers and practitioners from around the world gathered to share their latest research findings and emerging trends in machine learning for NLP, machine translation, language models, text mining, information extraction, and many more.

In the 'Writing Code for NLP Research' tutorial, researchers from Allen AI Institute shared their best practices learned from designing the development of the Allen NLP toolkit, a PyTorch-based open-source library for deep learning NLP research. It was an excellent tutorial to learn practical advice on writing research code and to recognize the importance of having good quality codes. In the 'Deep Latent Variable Models of Natural Language' tutorial, deep latent variable models were covered, which are emerging as a useful tool in NLP applications. Mainly, three types of latent variable models (discrete, continuous, and structured) and inference strategies (exact gradient, sampling, and conjugacy) over the latent variables were examined.

There were a number of presentations/papers in the clinical domain. One of the interesting papers, titled 'emrQA: A Large Corpus for Question Answering on Electronic Medical Records', proposed a novel semi-automated framework to generate domain-specific large-scale question answering (QA) corpus by leveraging expert annotations on clinical notes for various NLP tasks from the i2b2 challenge datasets. For medical QA on EMR, they released 400K+ question-answer evidence pairs and 1M question-logical forms, a representation useful for generating corpus. Generating patient-specific QA from an EMR is an important NLP task to process a natural language question and provide a human level accuracy answer. Among many datasets that were presented at the conference, a clinical domain dataset MedNLI was included. MedNLI is a Natural Language Inference (NLI) dataset on the medical history of patients annotated by physicians, which we can later refer in our research.

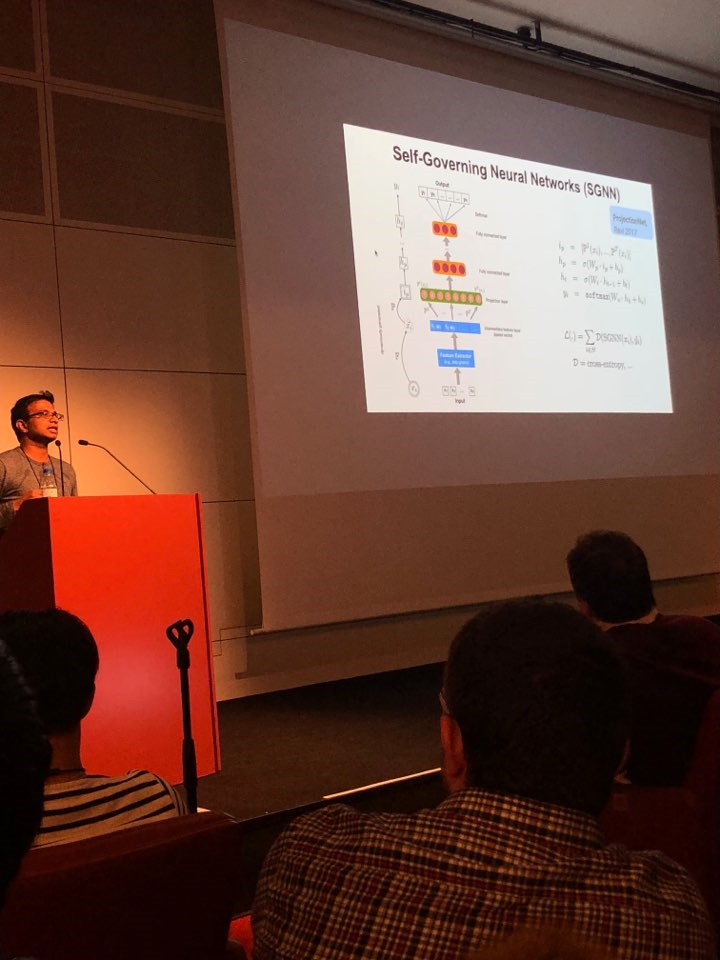
In a paper presented by
Google Research, titled '
Self-Governing Neural Networks for On-Device Short Text Classification', researchers described on-device Self-Governing Neural Networks (SGNNs) that achieve state-of-the-art results in dialog related tasks. SGNN uses locality sensitive hashing, a technique for dimensionality reduction in data for clustering. As a result, the embedding layer for their on-device architecture has dropped to 300K parameters compared to other methods having millions of parameters. The proposed method is useful for text classification applications that significantly save storage cost and improve computational performance.
As newcomers to the field focusing on data-driven approaches to NLP, this conference was challenging but worthwhile to see cutting-edge research in NLP. We sure took some inspirations from the conference for our new research to develop a dimensionality reduction model for assessing clinical trials feasibility. We hope to attend the next year's EMNLP conference in Hong Kong!
Okay, below are two cuts of the so-called "Beauty and the Beast." Funny, isn't it?







 HOME
HOME








